Using AI to Generate Database Query Is Cool. But What About Access Control?


Large Language Models have shown the world its incredible versatility. One of its most remarkable powers is to turn fuzzy human language into executable code. This not only helps engineers improve their productivity but also enables non-technical people to achieve what used to require help from developers.
Generating analytical data queries is one of the most popular use cases of LLM-based code generation. What can be cooler for business analysts than to ask a question in plain human language and get a visualization in seconds? Traditionally, only big boys like PowerBI and Google Sheets could offer features like that, but now LLM has democratized AI capabilities and lowered the bar. In this post, I'll demonstrate a simple implementation and will also cover an important but often overlooked topic: access control.
Requirements
Suppose we have an e-commerce store selling electronics, furniture, and outdoor gear. The store has the following (greatly simplified) data model:
Our imaginary scenario is that the business analyst wants to ask analytical questions about the store's data in plain English and get back charts. An example question could be: "Show me the total sales of products by category".
To add one more twist, we also want to make sure that the analyst can only access data that they are authorized to see. Each analyst user has an assigned "region", and they can only see data from that region.
Stack
Here are the frameworks and libraries used for building this demo:
- Remix.run as full-stack framework
- Langchain for interfacing with OpenAI API
- Prisma ORM for data modeling database access
- ZenStack for access control
- Charts.js for creating diagrams
Implementation
You can find the finished project code at the end of this post.
General Workflow
The general workflow of the implementation looks like this:
One key difference between this demo and other AI-based data query projects is that we chose to generate Prisma queries instead of raw SQL. This choice has both upsides and downsides:
- ⬆️ Prisma query is more portable. We don't need to deal with SQL dialects.
- ⬆️ It's safer as we can easily exclude write operations without complex SQL parsing and validation.
- ⬆️ Prisma query is much less flexible than SQL, which tends to reduce the complexity of reasoning.
- ⬇️ LLMs obviously have a lot more SQL training data compared to Prisma query code. This probably largely cancels the previous upside.
- ⬇️ Prisma query is a lot less expressive than SQL for analytical tasks.
There's one more reason why we chose to do that, and you'll see it in the next section, where we talk about access control.
Data Modeling
The Prisma schema for our demo is very straightforward:
// Analyst user
model User {
id String @id @default(cuid())
email String @unique
password String
createdAt DateTime @default(now())
updatedAt DateTime @updatedAt
// the assigned region, this controls what data the user can access
region String
}
// Product
model Product {
id String @id @default(cuid())
name String
category String
price Float
orderItems OrderItem[]
}
// Order
model Order {
id String @id @default(cuid())
createdAt DateTime @default(now())
updatedAt DateTime @updatedAt
items OrderItem[]
region String
}
// Order item
model OrderItem {
id String @id @default(cuid())
quantity Int
productId String
orderId String
product Product @relation(fields: [productId], references: [id], onDelete: Cascade)
order Order @relation(fields: [orderId], references: [id], onDelete: Cascade)
}
// Helper view for joining orders, order items, and products
view OrderItemDetail {
id String @id
createdAt DateTime
updatedAt DateTime
region String
product String
category String
unitPrice Float
quantity Int
subtotal Float
}
Prompt Engineering
As with all applications involving LLM, the most challenging part is to come up with the right prompts. In our demo, we need to devise two prompts, one for turning human language into Prisma queries and another for turning query result datasets into Charts.js configuration. The model of choice is OpenAI's "gpt-4".
Prompt for Prisma Query Generation
The first interaction with LLM is to turn a natural language question into a Prisma query.
System message:
You are a senior developer who knows Prisma ORM very well.
User message:
Given the following Prisma schema:
{schema}
The "OrderItemDetails" view contains order items with more fields joined from "Order" and "Product". You can use it for aggregations.
When you do aggregation, use "_sum", "_avg", "_min", "_max" to aggregate numeric fields, use "_count" to count the number of rows.
An aggregation can be written like:
{
by: ['field'],
_sum: {
metricField: true,
},
}
Using Prisma APIs including "findMany", "aggregate", and "groupBy", compute a Prisma query for the following question:
{query}
However, don't return the Prisma function call, instead, transform it into a JSON object like the following:
{
"model": "Order",
"api": "findMany",
"arguments": { ... }
}
The "model" field contains the name of the model to query, like "Order", "OrderItemDetails".
The "api" field contains the Prisma API to use, like "groupBy", "aggregate".
The "arguments" field contains the arguments to pass to the Prisma API, like "{ by: ['category'] }".
Return only the JSON object. Don't provide any other text.
The LLM gives output like:
{
"model": "OrderItemDetail",
"api": "groupBy",
"arguments": {
"by": ["category"],
"_sum": {
"subtotal": true
}
}
}
We can then translate it into Prisma query like:
prisma.orderItemDetail.groupBy({
by: ['category'],
_sum: {
subtotal: true,
},
});
, and get back a result dataset like:
[
{
"_sum": {
"subtotal": 1099
},
"category": "Electronics"
},
{
"_sum": {
"subtotal": 2199
},
"category": "Furniture"
},
{
"_sum": {
"subtotal": 307
},
"category": "Outdoor"
}
]
Why not just generate the entire Prisma call directly?
You've noticed that we forced the LLM to generate a structured JSON for the Prisma query instead of the query function call itself. The reason is that you should never trust and execute code coming from an external source, and AI is no exception. By generating JSON instead of code, we can further inspect it, filter it (e.g., only allow "read" method calls), and restrain the code executed.
Prompt for Charts.js Configuration Generation
The goal of the second interaction with LLM is to turn the query result dataset into a Charts.js configuration object.
System message:
You are a senior developer who knows Charts.js very well.
User message:
Generate a bar chart using Charts.js syntax for the following JSON data:
{data}
Use the chart configuration that you feel is most appropriate for the data.
Return only the Charts.js input object converted to JSON format.
Make sure keys and string values are double quoted.
Don't call Charts.js constructor. Don't output anything else.
The LLM gives output like the following, which we can directly pass to Charts.js:
{
"type": "bar",
"data": {
"labels": ["Electronics", "Furniture", "Outdoor"],
"datasets": [
{
"label": "Subtotal",
"data": [1099, 2199, 307],
"backgroundColor": ["rgba(255, 99, 132, 0.2)", "rgba(54, 162, 235, 0.2)","rgba(255, 206, 86, 0.2)"],
"borderColor": ["rgba(255, 99, 132, 1)","rgba(54, 162, 235, 1)","rgba(255, 206, 86, 1)"],
"borderWidth": 1
}
]
},
"options": {
"scales": {
"yAxes": [{
"ticks": {
"beginAtZero": true
}
}]
}
}
}
Give It A Try
After hooking everything up, we can now try it out. Here's a quick demo:
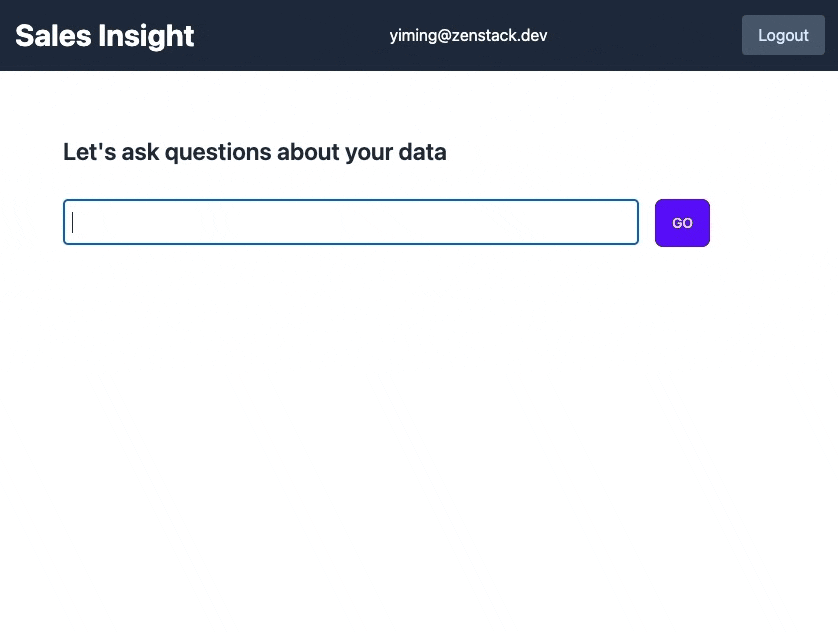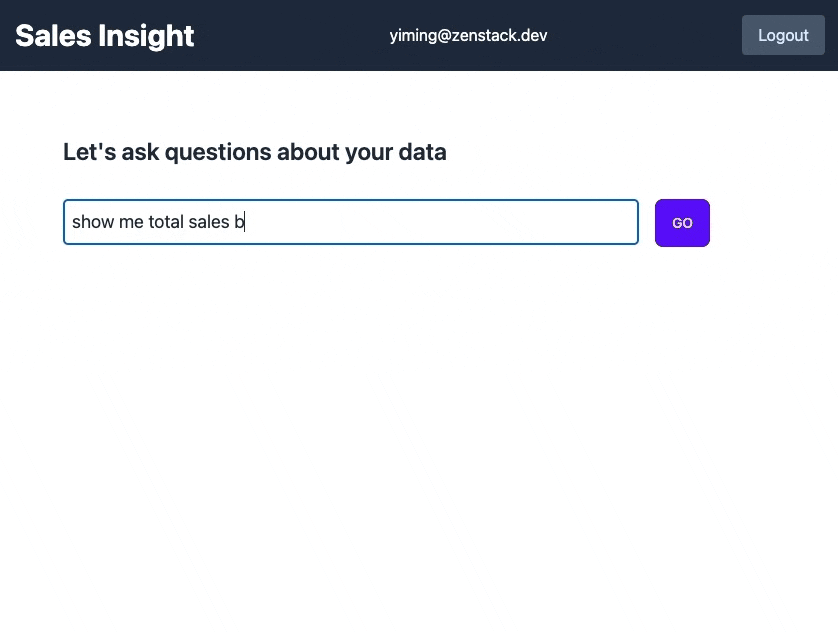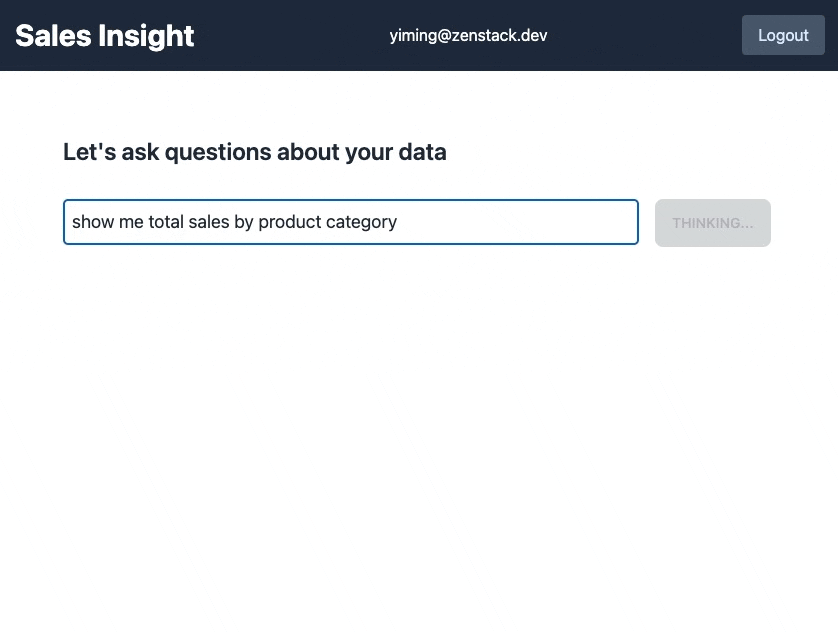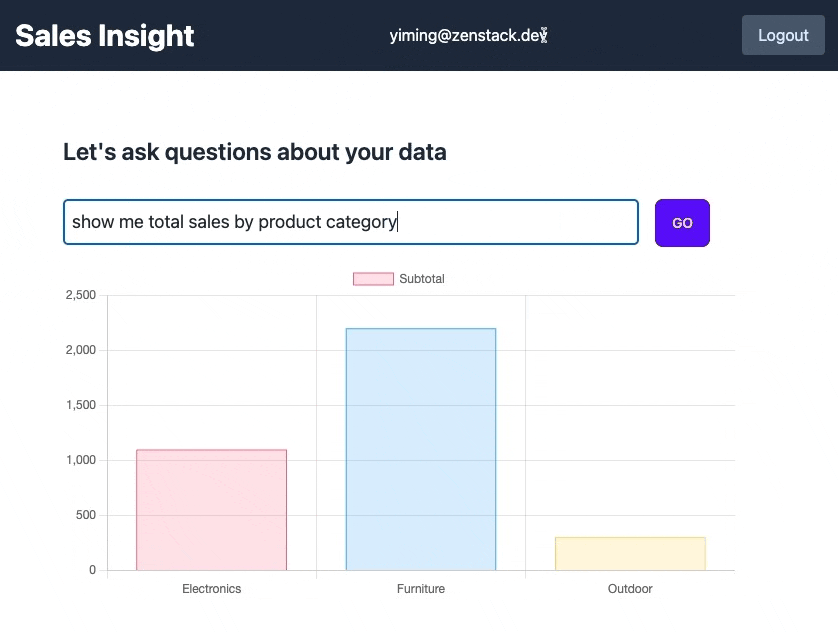
It's quite slow because of OpenAI API latency (the recording is fast-forwarded), and it still can't reliably handle many cases. But still very cool, isn't it?
What About Access Control?
Looking back at our requirements, we'll find a significant part still missing: access control. An analyst should only see data from their assigned region. How can we ensure that the generated Prisma queries only return data from the right region? Our current implementation included all data in the query result.
In general, if you want to impose access control into LLM-based query generation, there are several possible solutions:
- If you use PostgreSQL, you can set up row-level-security and hook it up with your user system, but it's non-trivial.
- If you do SQL generation, you can use a SQL parser to post-process the generated query and inject extra filtering conditions.
- If you generate Prisma queries as we do here, you can inject extra filtering conditions into the generated query object. Here's the nice thing: ZenStack can do it automatically for you.
ZenStack is a toolkit built above Prisma. It makes many powerful extensions to Prisma, and those relevant to our discussion are:
- Schema extensions that allow you to define access control policies
- Runtime extensions that enforce access control automatically
To leverage ZenStack, we'll use the modeling language called ZModel (instead of Prisma schema) to define data models and access policies in one place. Here's what it looks like:
model Product {
...
// 🔐 login is required to read products
@@allow('read', auth() != null)
}
model Order {
...
// 🔐 analysts can only read orders of their assigned region
@@allow('read', auth().region == region)
}
model OrderItem {
...
// 🔐 analysts can only read order items of their assigned region
@@allow('read', auth().region == order.region)
}
view OrderItemDetail {
...
// 🔐 analysts can only read order details of their assigned region
@@allow('read', auth().region == region)
}
A few quick notes:
- The data modeling is exactly the same as with the Prisma Schema Language
- The
@@allowattribute is used for defining access control policies - All access is denied by default unless explicitly allowed
- The
auth()function returns the current user in session
At runtime, when we need to query data with Prisma, we can substitute PrismaClient with an enhanced version provided by ZenStack, which will automatically inject access control conditions into the query object.
// get user id from session
const userId = await requireUserId(request);
// fetch the user
const user = await prisma.user.findUniqueOrThrow({
where: { id: userId },
select: { id: true, region: true },
});
// create an enhanced PrismaClient
const db = enhance(prisma, { user });
// use the enhanced PrismaClient to query data, e.g.:
// db.orderItemDetail.groupBy({ ... })
After making these changes, we can see that different analysts see different results for the same question:
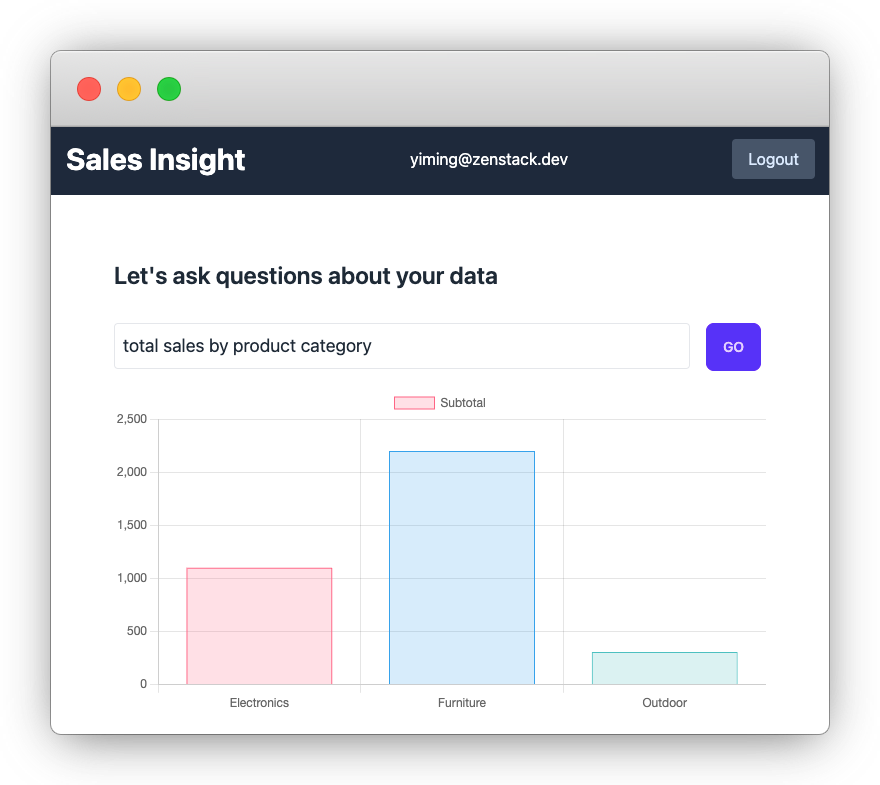
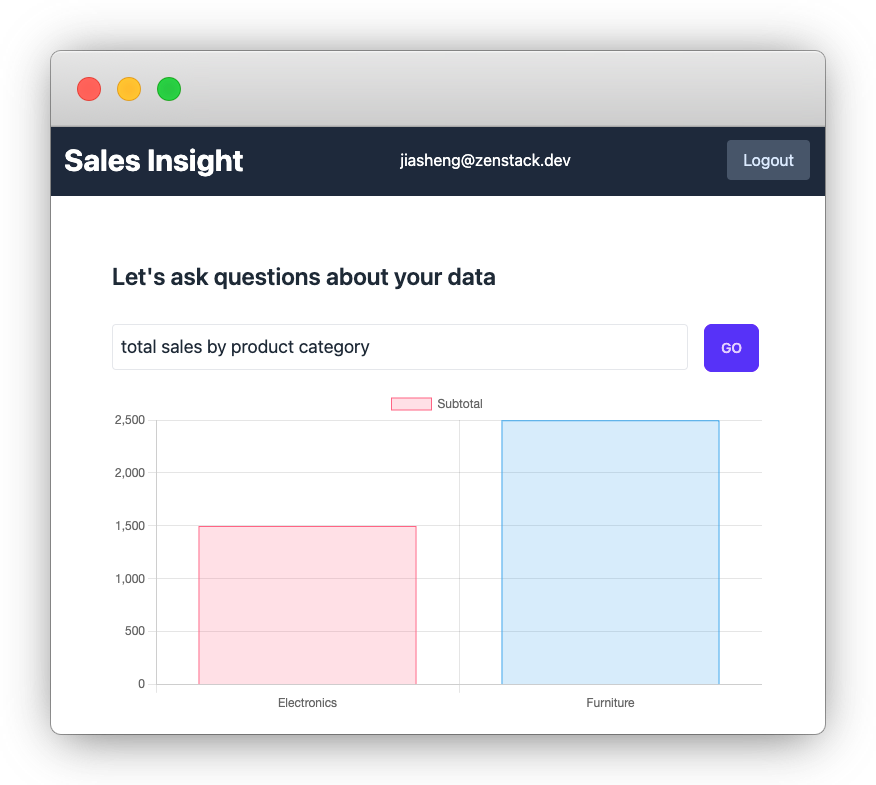
Project Code
You can find the finished project code at https://github.com/ymc9/llm-data-query.
Challenges
By combining the right set of tools and the power of LLM, we've built a nice little Business Intelligence system with surprisingly little effort. It was unimaginable before the dawn of Generative AI. However, there are still many challenges to overcome to make it a production-ready system:
- GPT-4's generation speed is too low, and GPT-3.5's generation quality is not good enough. Fine-tuning is likely needed to improve both speed and quality.
- Hallucination is a major problem. The LLM can invent query syntax that Prisma does not support. Again, fine-tuning (or more prompt engineering) can improve it.
- Prisma's query syntax is too limited for analytical tasks. There are already various related GitHub issues but it's not clear when they'll be implemented.
- Finally, LLM's inherent nondeterminism makes it hard to get consistent results when repeating the same question, which can confuse users.
Building real-world products with LLM is still a challenging journey that requires us to invent patterns and tricks that didn't exist before.